System susses out silent speech
By
Eric Smalley,
Technology Research NewsWhen you talk there's a lot more going on than just sound.
Scientists from the NASA Ames Research Center are taking advantage of the nerve activity that happens near the throat when humans speak in order to gain information about what a person is saying.
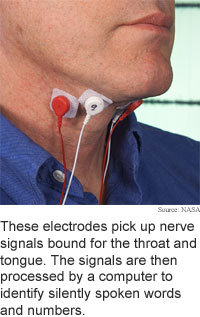
The researchers have shown that the sub auditory, or silent electrical signals in the throat can be tapped for speech recognition interfaces and communications. The researchers capture signals through two pairs of sensors stuck under the chin and on either side of the throat and use a computer to interpret the signals. These nerve signals -- muscle control signals that the brain sends to the tongue and vocal cords -- are present whether a person speaks audibly or silently.
The method could be used to augment acoustics in noisy environments, in computer speech recognition, and in space where acoustics are distorted by unusual breathable gas mixtures and different pressures, said Chuck Jorgensen, chief scientist for neural engineering at NASA Ames Research Center. "Subvocal methods can augment the speech to minimize errors," he said.
It could also eventually be used when privacy is needed, for injured or handicapped users, and to add information like mood, fatigue or intent to the communications channel, said Jorgensen.
The researchers' prototype recognizes six words and the digits 0 through 9, and has an accuracy rate of 92 percent, according to Jorgensen.
The researchers have constructed a pair of prototype applications. The first uses subvocal signals to allow a user to browse the Web. A user silently speaks numbers to spell out two-digit codes that represent each letter of a search term. The search results are numbered, and a user silently speaks the numbers to choose Web pages.
The second application allows a user to silently control a Mars rover. "We have a real-time control demo of a Mars rover which we can sub vocally move around terrain," said Jorgensen them. The prototype uses the words stop, go, left, right, alpha, and omega. Alpha and omega are general control words that represent pairs of functions like faster/slower or up/down depending on context.
The system discerns words from the electromyelogram/electropalatogram (EMG/EPG) readings of nerve signals that control vocalization in larynx and tongue muscles. The system learns to match features in the waveforms of the readings to the six words and 10 digits. A user must first train the system by saying the words and digits repeatedly.
The nerve signals are measured by sensors attached to the skin on the side of the throat to pick up signals bound for the larynx, and on the soft tissue under the chin to pick up signals bound for the tongue.
A user is able to speak silently using the method because the signals are tapped at a point before they are used to vocalize speech. The method picks up signals when a person is speaking silently using almost no muscle movement, according to Jorgensen.
Key to the method is that vocal muscle control signals must be very precise and repeatable in order for speech to be understood by other people.
The researchers used a mixed wavelet/neural network coding scheme to analyze the signals, said Jorgensen. The muscle signals picked up by the sensors are amplified and filtered to tease out certain patterns present in the waveforms, then the information is fed into a neural network pattern classifier that learns and organizes the signal patterns in real time.
Neural networks mimic biological brains and have the capacity to learn. They're composed of simple processor units that are comparable to neurons. The connections among the units get stronger the more they are used, and repeated exposure to the same or similar information produces a distinct neural pattern that can be used to identify subsequent input.
The researchers first presented the work in July, 2003 at the International Joint Conference on Neural Networks in Portland, Oregon. Since then they have made the system work in real time and decreased training time, said Jorgensen. "We have dropped the learning requirements from several hundred examples to 50 or less per word, and can train in the morning and be running in the afternoon," he said.
The researchers are now working on using the method in full-blown speech recognition systems, said Jorgensen. "We're working on vowel and consonant separation," he said.
They are also testing new sensors that can read muscle signals through clothing. "We're developing an entirely new sensor architecture based not on surface electrodes, but on capacitive field coupling," said Jorgensen.
The method could be used in practical applications that contain limited vocabularies in less than three years, said Jorgensen. It will be more like five years before the method can be used in connection with full-blown speech recognition systems, he said.
Jorgensen's research colleagues were Diana D. Lee and Shane Agabon. The research was funded by the National Aeronautics and Space Administration (NASA).
Timeline: > 3 years
Funding: Government
TRN Categories: Human-Computer Interaction
Story Type: News
Related Elements: Technical paper, "Sub Auditory Speech Recognition Based on EMG/EPG Signals," International Joint Conference on Neural Networks (IJCNN), Portland, Oregon, July 2003.
Advertisements:
March 24/31, 2004
Page One
Molecular logic proposed
System susses out silent speech
Virtual people look realistically
Pulse trap makes optical switch
Briefs:
Irregular layout sharpens light
Bacteria make clean power
Curve widens 3D display
Triangles form one-way channels
DNA has nano building in hand
Nanowires span silicon contacts
News:
Research News Roundup
Research Watch blog
Features:
View from the High Ground Q&A
How It Works
RSS Feeds:
News
Ad links:
Buy an ad link
| Advertisements:
|
 |
Ad links: Clear History
Buy an ad link
|
TRN
Newswire and Headline Feeds for Web sites
|
© Copyright Technology Research News, LLC 2000-2006. All rights reserved.