Hearing between the lines
By Kimberly Patch, Technology Research NewsWhen humans talk, we exchange a lot of audio information along with the words. Computers, however, don't hear between the lines, which is one reason speech recognition applications can seem so frustratingly stupid. Essentially, today's computers are socially inept, blind to the meanings of subtle pauses or even drastic changes in tone.
The technical reason for this is the Hidden Markov Model (HMM) most speech recognition programs rely on only looks at tiny, 10 millisecond slices of speech. The model works well for picking out words, but misses contextual cues that span words, phrases or sentences.
"When you pause at the end of the sentence or you lengthen or you drop your pitch, that [spans] a region that's at least 10 times larger than the HMM can capture and sometimes 100 times larger," said Elizabeth Shriberg, a senior research psycholinguist at SRI International.
Hoping to remedy the situation, Shriberg and other researchers have shown in a pair of experiments that computers can use speech attributes like prosody -- information gleaned from the timing and melody of speech -- to better understand human speech.
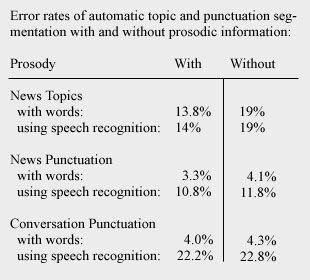
In one experiment, prosody significantly improved a computers accuracy in adding punctuation and paragraphs to databases of speech from news broadcasts and phone conversations. Prosody proved even more helpful in sorting the broadcast feed into topics. (See chart)
Prosody includes the duration, pitch and energy of speech. Duration, or the way people stretch or speed certain parts of speech, is most important, said Andreas Stolcke, a senior research engineer at SRI International. "People use the duration of speech sounds in certain ways to emphasize things," he said.
The researchers found that pauses and pitch were most useful in segmenting news speech, while pauses, duration of syllables and word based cues proved significant in the more difficult task of segmenting natural conversation.
Prosodic information is slowly being recognized as an important source of information in speech understanding, said Julia Hirschberg, Technology Leader in the Human-Computer Interface Research Department at AT&T Labs. "The SRI work applies prosodic information to a very important task, topic segmentation, with considerable success. [It's] the first that I know of which improves topic segmentation performance," she said.
In another experiment, researchers used word choice and order as well as prosodic cues to improve the task of automatically categorizing telephone conversations into 42 types of phrases like statements, opinions, agreement, hedging, repeated phrases, apologies, and phrases that signal non-understanding.
Prosody's ability to mark emotional levels of speech may eventually help in certain types of searches, like news footage of politicians having an argument. A similar, real-time, application could be call center operators wanting to know "who the angry customers are right away because you don't want them to have to [continue listening] to a computer," said Shriberg. Prosody also allows computers to gauge attention levels, which may allow educational applications to automatically adjust the difficulty of a task. Prosodic information, because it differs among languages, may also prove useful in discerning what language is being spoken.
The researchers are also looking at using prosody to make speech recognition more accurate -- "the holy grail right now," said Stolcke. "The general idea is simply to have a more comprehensive model of everything that can vary within speech. [You] can get significantly better speech recognition if you know the type of utterance," he said.
Better recognition based on prosody is also likely to create a feedback loop that will make talking to computers more natural, said Shriberg. "If the machine is using [pitch and emphasis, people] will put that in their speech because it's getting a response from the machine. They'll adapt to what the machine is able to do -- that's a well-known principle."
Real world applications of prosody are at least two years away, said Shriberg.
Shriberg and Stolcke were joined in the prosody topic segmentation research by Dilek Hakkani-Tür and Gökhan Tür of Bilkent University in Ankara, Turkey. They were joined in the automatic tagging of conversational speech research by Noah Coccaro and Dan Jurafsky of the University of Colorado Boulder, Rebecca Bates of the University of Washington, Paul Taylor of the University of Edinburgh, Carol Van Ess-Dykema of the U.S. Department of Defense, Klaus Ries of Carnegie-Mellon University and the University of Karlsruhe in Germany, Rachel Martin of Johns Hopkins University and Marie Meteer of BBN Technologies.
The researchers' work on prosody for topic segmentation was funded by the National Science Foundation (NSF) and the Defense Advanced Research Projects Agency (DARPA). The work on automatic tagging of conversational speech was funded by the Department of Defense (DOD).
Timeline: > 2 years; > 5 years
Funding: Government
TRN Categories: Databases and Information Retrieval; Human-Computer Interaction
Story Type: News
Related Elements: Technical paper "Prosody-Based Automatic Segmentation of Speech into Sentences and Topics" posted in the Computing Research Repository; Technical paper "Dialog Act Modeling for Automatic Tagging and Recognition of Conversational Speech," posted in the Computing Research Repository
Advertisements:
July 19, 2000
Page One
Hearing between the lines
Search tool finds answers before queries
Scatter could boost fiber capacity
Software makes data really sing
Magnetic microscope recovers damaged data
News:
Research News Roundup
Research Watch blog
Features:
View from the High Ground Q&A
How It Works
RSS Feeds:
News
Ad links:
Buy an ad link
| Advertisements:
|
 |
Ad links: Clear History
Buy an ad link
|
TRN
Newswire and Headline Feeds for Web sites
|
© Copyright Technology Research News, LLC 2000-2006. All rights reserved.